You configure the data lake in this step. It will be little long one because you first create database and then configure crawler to create data catalog table using the data in the Redshift Database.
-
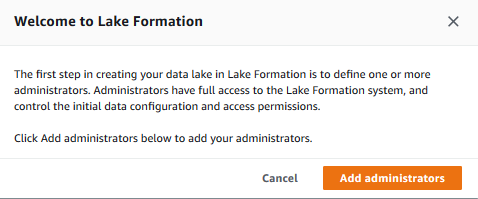
Open the AWS Lake Formation console. If you are using Lake Formation for the first time in the region, it will ask you to create a data lake administrator. A data lake administrator is an IAM user or IAM role that performs administrative tasks on the data lake. For the first time user, it will popup a message to add administrators. Click on the Add administrators button to create administrators for your Data Lake.
-
Select your AWS logged-in IAM user from the drop down list. For the rest of workshop, the user will be considered as a data lake administrator and will have full access to the data lake. Click on the Save button.
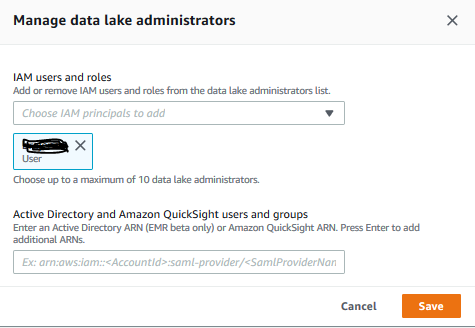
Note: if you did not get the popup then that means the data lake already has an administrator. You can check that by clicking on the “Admins and database creators” menu in the left. If you see that your logged-in IAM username is listed as the “Data lake Adminstrator” then you are ok to move to the next step. Otherwise, click on the “Grant” button to add “your AWS logged-in IAM user” as the administrator of the data lake.
-
After adding the administrator, you will create the database. On the AWS Lake Formation console, click on the Databases option on the left menu and then click on Create database button.

-
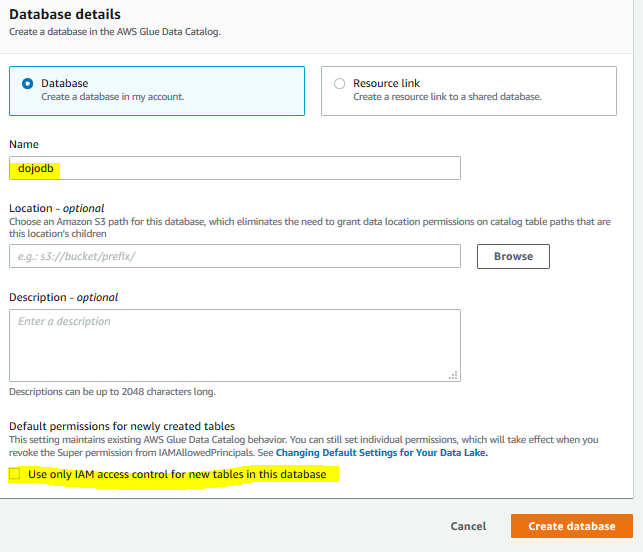
On the next screen, Select database option. Enter dojodb as the Name. Make sure you Uncheck the option - Use only IAM access control for new tables in this database. Leave rest of the options as default and click on Create database button.
-
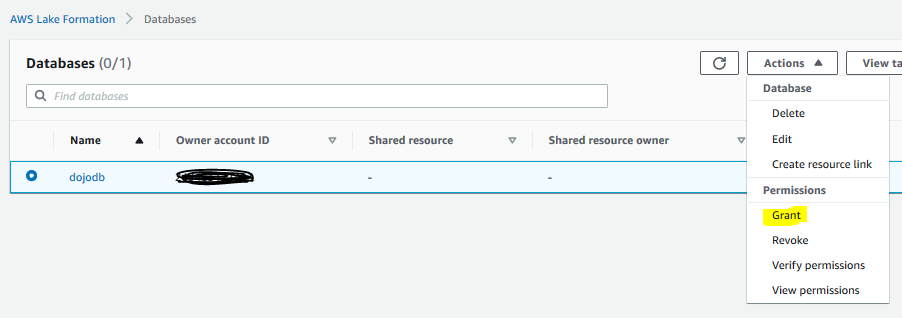
The database is added in no time. You now provide Glue IAM Role access to the database. The IAM role is used by the crawler to create catalog table in the database. Select the database and click on the Grant option under the Action menu.
-
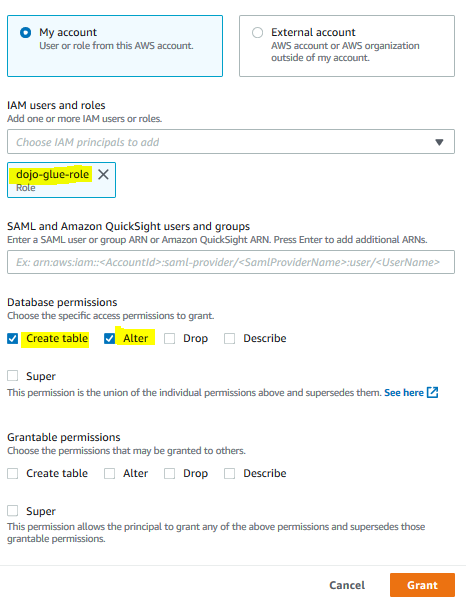
On the next screen, select My account option. Select dojo-glue-role for the IAM users and roles field. Check Create table and Alter options for the database permissions. Finally click on the Grant button.
-
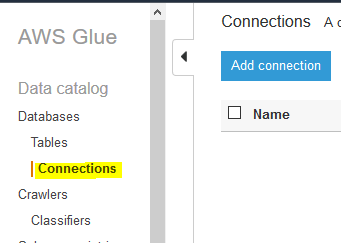
The database access granted to the role. It is time to create the crawler to catalog the table. First you create Glue Connection to the Redshift database and then you configure and run the crawler. Goto Glue Management console, select Connections menu in the left and then click on the Add connection button.
-
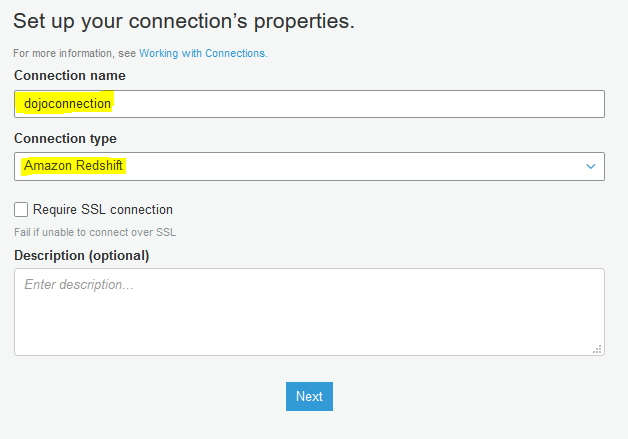
On the next screen, type in dojoconnection for the connection name. Select Amazon Redshift as the connection type. Click on the Next button.
-
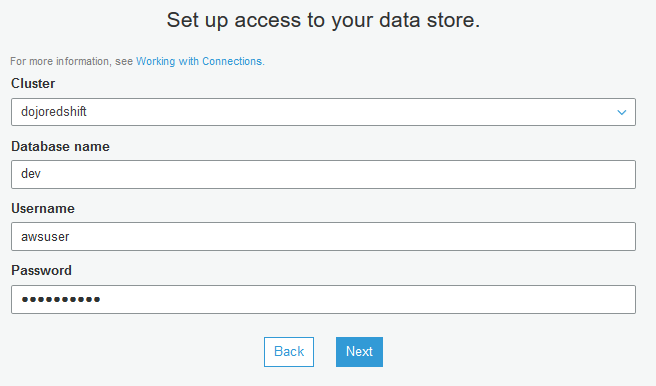
On the next screen, select dojoredshift for the cluster. Type in Password1! for the password. Click on the Next button.
-
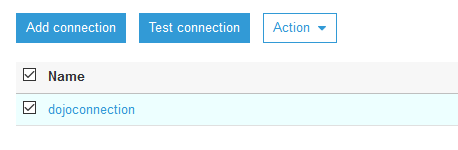
On the next screen, click on the Finish button to create the connection. When the connection is created, select the connection and click on the Test connection button.
-
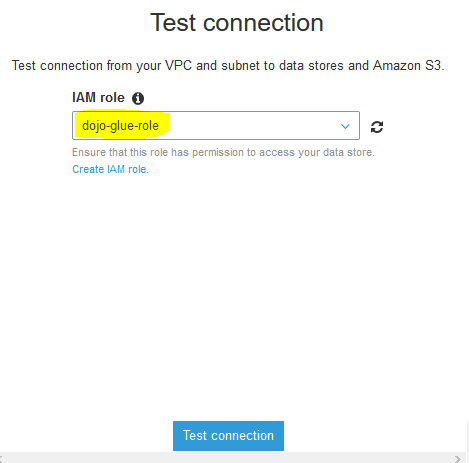
On the popup window, select dojo-glue-role as the IAM Role and click on the Test connection button.
-
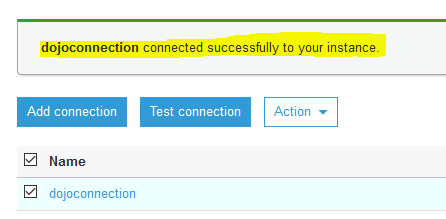
The connection testing will start. Wait till you see connection status as Successful.
-
The connection is ready. It is time to create the crawler. In the Glue Management console, click on the Crawlers menu in the left and then click on the Add crawler button.
-
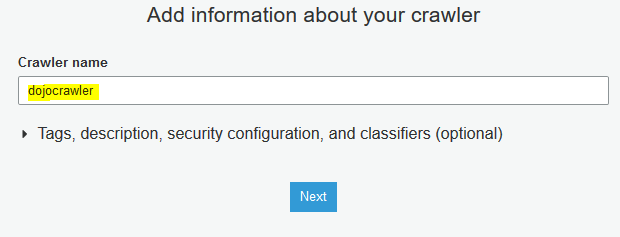
On the next screen, type in dojocrawler as the crawler name and click on the Next button.
-
On the next screen, select Data stores for the Crawler source type and select Crawl all folders for the Repeat crawls of S3 data stores fields. Click on the Next button.
-
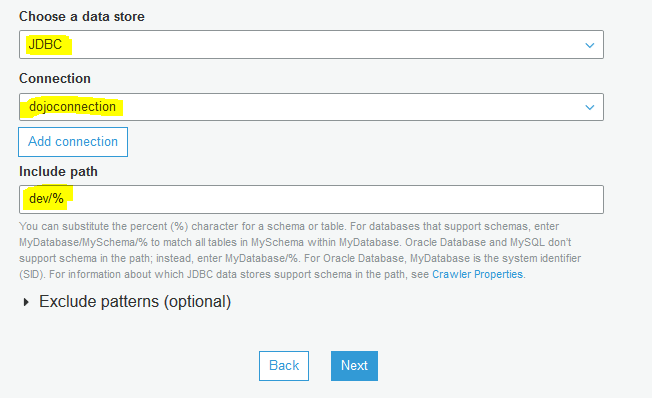
On the next screen, select JDBC as the data store. Select dojoconnection as the connection. Type in dev/% for the include path as you want to catalog all the tables in the dev database. Click on the Next button.
-
On the next screen, select No for Add another data store and click on the Next button.
-
On the next screen, select dojo-glue-role as the IAM role and click on the Next button.

-
On the next screen, for the crawler run frequency, select Run on demand and click on the Next button.
-
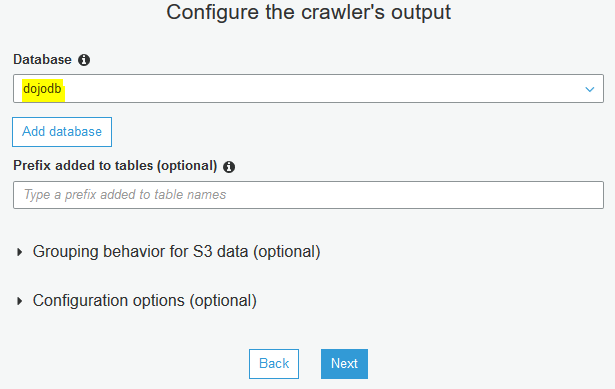
On the next screen, select dojodb as the database and click on the Next button.
-
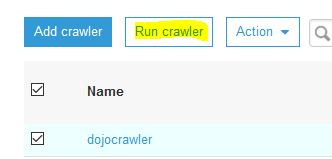
On the next screen, click on the Finish button. The crawler is created in no time. Select the crawler and click on the Run crawler button.
-
The crawler will run and it will take some time to finish. The crawler will create one table as the Redshift database has just one table.

-
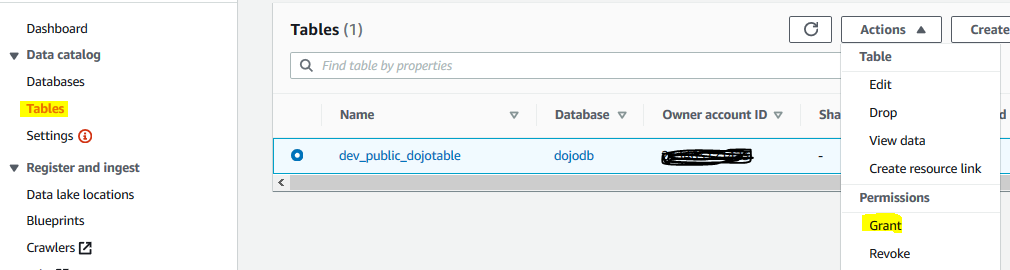
Finally, you grant dojo-glue-role access to the table created by the crawler. Goto Lake Formation console. Select Tables menu in the left, then select dev_public_dojotable table and click on the Grant option under the Action menu.
-
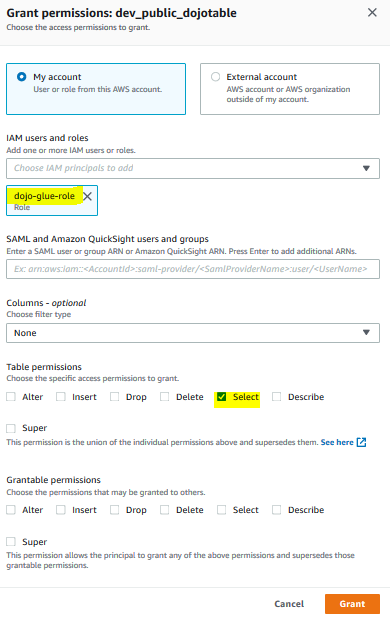
On the popup screen, select My Account option. Select dojo-glue-role for the IAM users and roles. Choose Select option for the Table permissions. Finally, click on the Grant button.
-
The table permission is ready. It also finishes the data lake configuration. Let’s create a developer endpoint and Jupyter notebook to see how to program with data lake which has Redshift database as the data source.