Before you configure data lake, you need to create Endpoint for S3 in the VPC where the Redshift Cluster is launched. It helps Glue connect to S3 bucker without going over the internet. The Redshift cluster has been launched in the default VPC. You will create S3 Endpoint in the Default VPC.
-
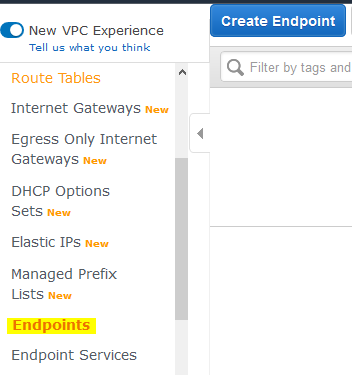
Goto VPC Management Console. Click on the Endpoints menu in the left and then click on the Create Endpoint button.
-
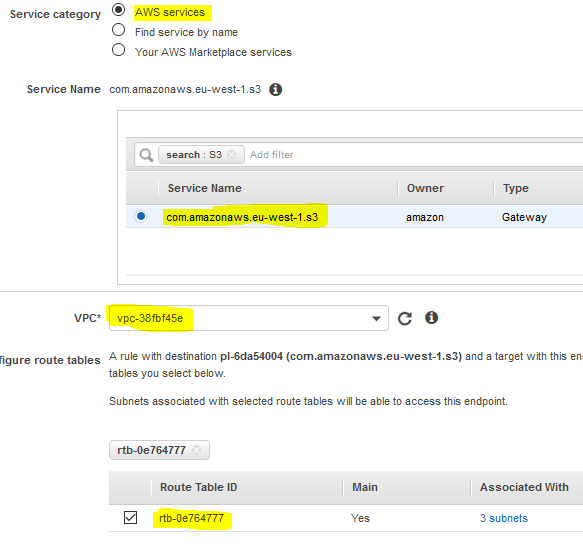
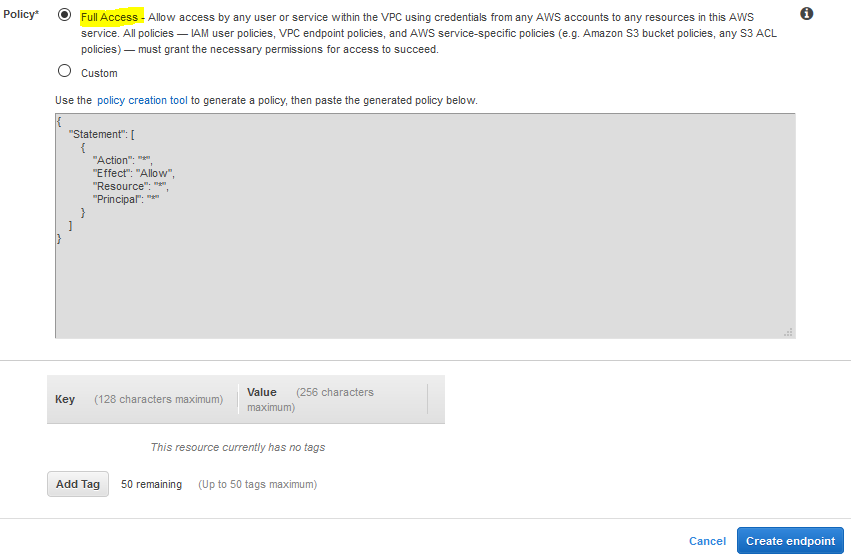
On the next screen, select AWS services for the service category. Select S3 for the service name. Select the default VPC for the VPC field. Select the default route table. Select Full Access for the policy and finally click on the Create endpoint button.
-
The endpoint is created. In the next step, you configure data lake end to end using Redshift as the data source.