You create a Glue Job which will read customers.csv data using the Glue Catalog and write to the target folder in the dojo-data S3 bucket. If you created bucket with a different name; then it will write there.
-
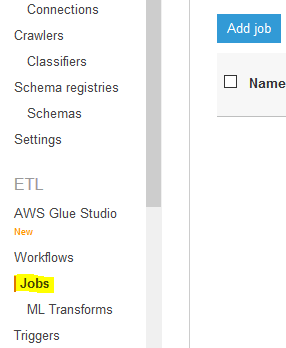
Goto Glue Management console. Click on the Jobs menu in the left and then click on the Add job button.
-
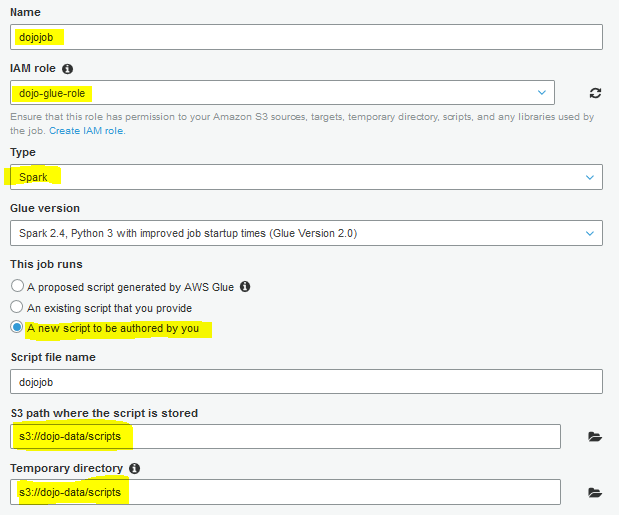
On the next screen, type in dojojob as the job name. Select dojo-glue-role for the IAM Role. Select Spark for type. Select A new script to be authored by you option. Select s3://dojo-data/scripts location for S3 path where the script is stored and Temporary directory fields. If you created bucket with a different name then replace dojo-data part with that name. Finally, click on the Next button.
-
On the next screen, click on the Save job and edit script button.
-
It will save the job and open the job editor. Copy-paste the following code for the job.
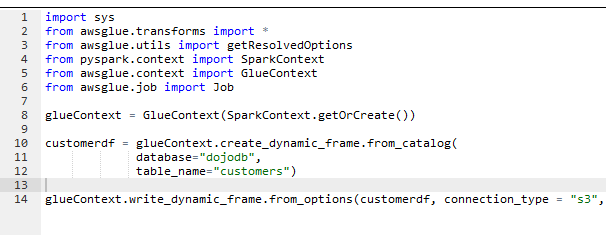
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job glueContext = GlueContext(SparkContext.getOrCreate()) customerdf = glueContext.create_dynamic_frame.from_catalog( database="dojodb", table_name="customers") glueContext.write_dynamic_frame.from_options(customerdf, connection_type = "s3", connection_options = {"path": "s3://dojo-data/target"}, format = "json")`
-
If you created the S3 bucket with a different name, replace dojo-data with that name. The code above is simple. You create Glue Context using SparkContext. You then create customerdf Dynamic Frame from the customers table in the dojodb database. You then simply convert the format of the data from csv to json and write back to the target folder in the S3 bucket.
-
You might be wondering that there is no customers table created in dojodb database as of now but you are using them in the job code. You should not worry for that because in the Glue Workflow, you will first run the crawler and then the job. That way, when the job runs, the customers table would have been created in dojodb database.
-
Click on the Save button to save the job script and then close the job editor.

-
The job and crawler are ready. It is time to orchestrate them in a Glue Workflow.