In this step, you configure AWS Glue Crawler to catalog the customers.csv data stored in the S3 bucket.
-
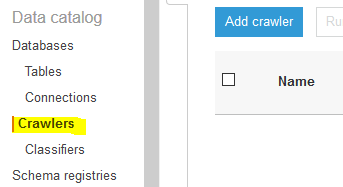
Goto Glue Management console. Click on the Crawlers menu in the left and then click on the Add crawler button.
-
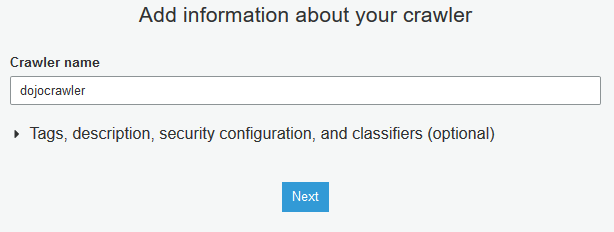
On the next screen, type in dojocrawler as the crawler name and click on the Next button.
-
On the next screen, select Data stores for the Crawler source type and select Crawl all folders for the Repeat crawls of S3 data stores fields. Click on the Next button.
-
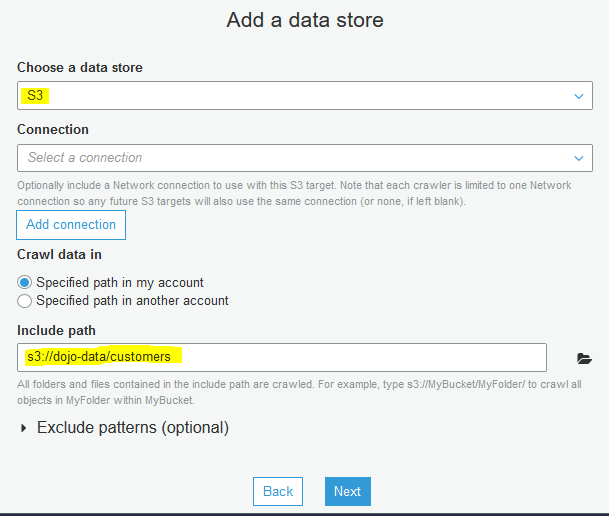
On the next screen, select S3 as the data store. Select Specified path in my account option for the Crawl data in field. Select s3://dojo-data/customers for the include path. If you created bucket with a different name; then use that bucket name. Click on the Next button.
-
On the next screen, select No for Add another data store and click on the Next button.
-
On the next screen, select Choose an existing IAM role option. Select dojo-glue-role as the IAM role and click on the Next button.

-
On the next screen, for the crawler run frequency, select Run on demand and click on the Next button.
-
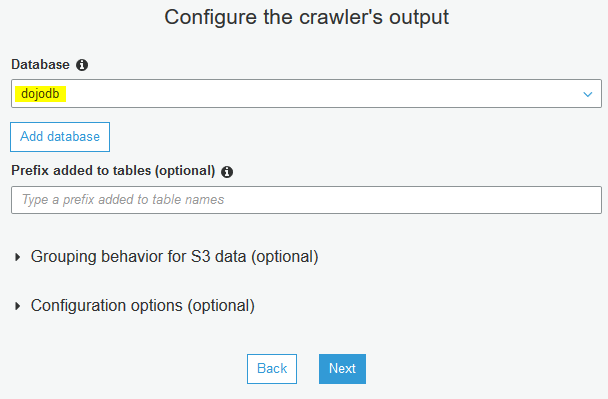
On the next screen, select dojodb as the database and click on the Next button.
-
On the next screen, click on the Finish button. The crawler is created in no time. You are not going to run the crawler now because you will configure a workflow later which will run the crawler.
-
In the next step, you create a Glue Job to process the S3 based data (customers.csv).