You launch EMR cluster which is used to process data using Glue Data Catalog and PySpark code.
-
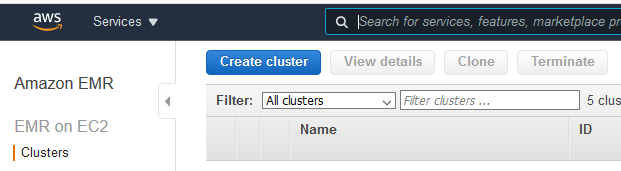
Goto the EMR Management console and click on the Create cluster button.
-
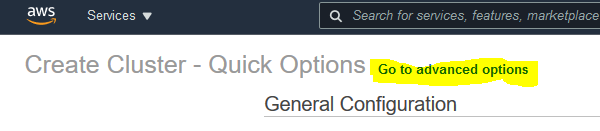
On the next screen, click on the Go to advanced options link.
-
On the next screen, use the default selection for the Release field. For the software configuration, make additional selection for JupyterEnterpriseGateway 2.1.0 and Spark 2.4.7 along with the default selection. Select Use for Spark table metadata option for the AWS Glue Data Catalog settings. Copy-paste the below JSON configuration into the software setting. Keep rest of the configuration to the default and click on the Next button.
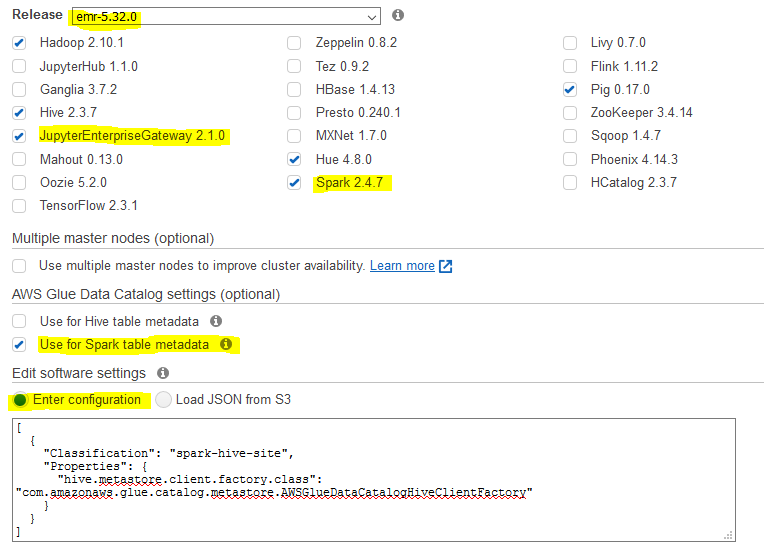
[ { "Classification": "spark-hive-site", "Properties": { "hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory" } } ]`
-
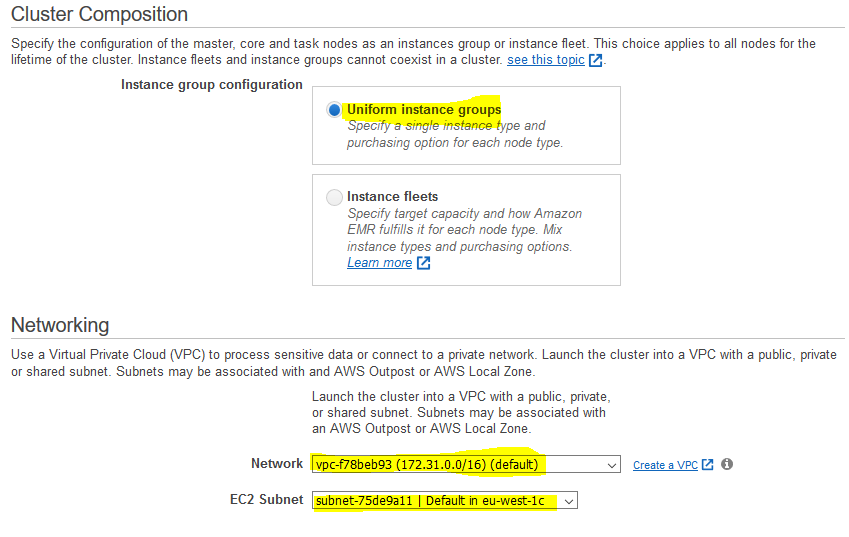
On the next screen, select Uniform instance groups for the Instance group configuration. Select default VPC for the network and select one the default subnet. Keep rest of the configuration to the default and click on the Next button.
-
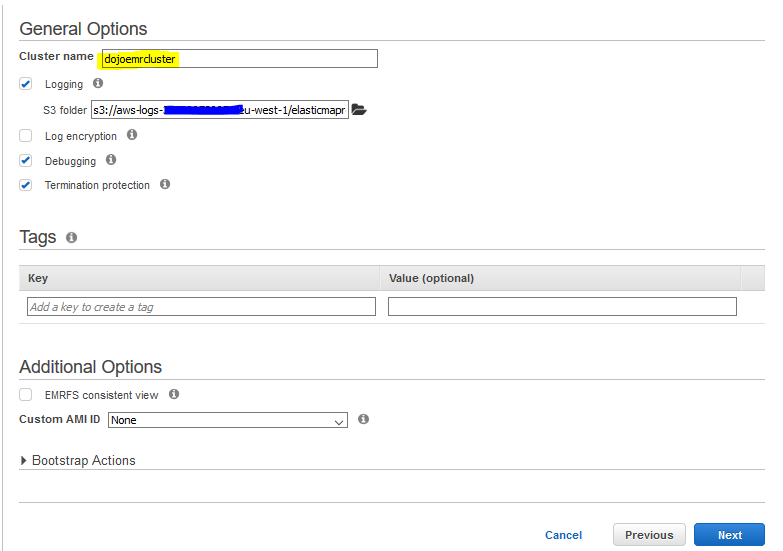
On the next screen, type in dojoemrcluster for the cluster name. Keep rest of the configuration to the default and click on the Next button.
-
On the next screen, keep the configuration to the default and click on the Create clsuter button.
-
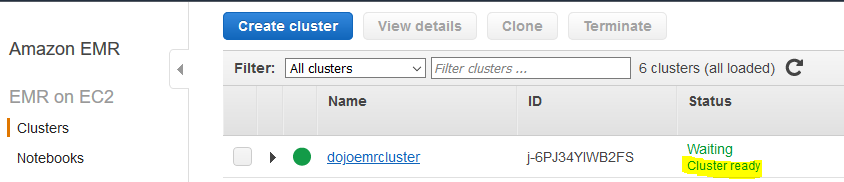
The cluster creation will start. It will take some time to finish. Wait till the cluster status changes to Cluster ready.
-
The cluster is ready. You now run a Jupyter Notebook Instance and try to access data using Glue Data Catalog.