You now run PySpark code to process S3 based data in the EMR Cluster using AWS Glue Catalog.
-
In the EMR Management console, on the dojoemrnotebook notebook page, click on the Open in Jupyter button.

-
It will open Notebook environment in a new browser tab or window. In Jupyter environment, click on PySpark option under the New menu.
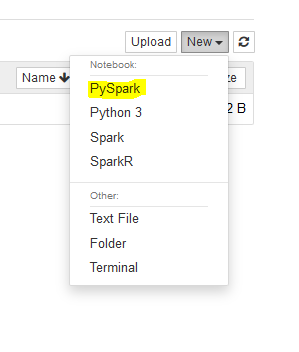
-
It will open Jupyter notebook IDE. It the cell, copy-paste the following code and run it. The code imports modules for the PySpark.
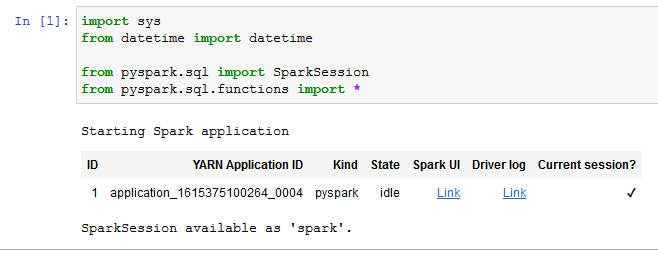
import sys from datetime import datetime from pyspark.sql import SparkSession from pyspark.sql.functions import *`
-
You copy-paste and run the following code to get the spark session.
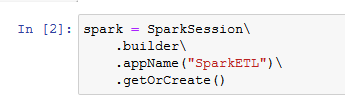
spark = SparkSession\ .builder\ .appName("SparkETL")\ .getOrCreate()`
-
You copy-paste and run the following code to read data from the customers Glue Catalog Table and then show the data loaded into the dataframe.
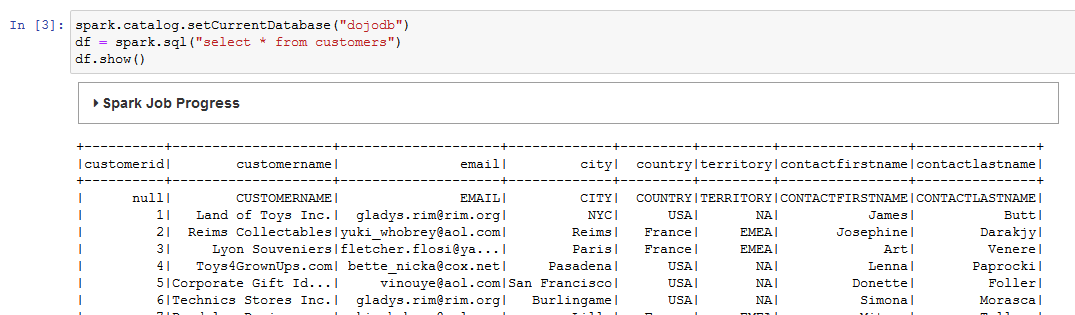
spark.catalog.setCurrentDatabase("dojodb") df = spark.sql("select * from customers") df.show()`
-
You copy-paste and run the following code to perform column select (for CUSTOMERNAME and EMAIL columns) transformation on the dataframe and then show the result.
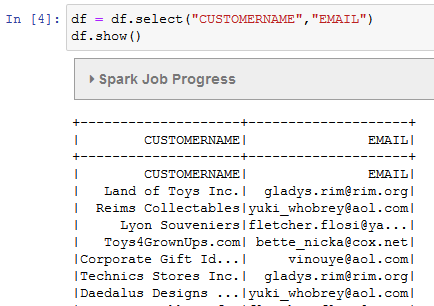
df = df.select("CUSTOMERNAME","EMAIL") df.show()`
-
Finally, run the following code to write the transformed data into the output folder in the S3 bucket. The data is also transformed from the csv to json format. If you created bucket with a different name then use that name here.

df.write.format("json").mode("overwrite").save("s3://dojo-lake/output/")`
-
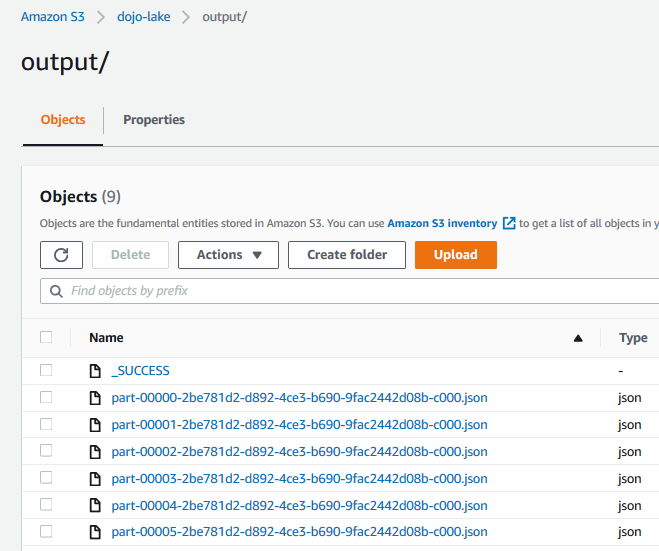
The code has written the output in the S3 bucket. You can verify it by navigating to the output location in the S3 bucket.
-
This finishes the workshop. Follow the next step to clean up the resources so that you don’t incur any cost post the workshop.