Building AWS Glue Job using PySpark - Part:2(of 2)
In Part-1 of the workshop, you learnt about setting up a data lake, creating development environment for PySpark and finally building a Glue job using PySpark.
In part-2, the focus is on learning PySpark for the ETL purpose. You must finish Part-1 of the workshop in order to start Part-2. Kindly complete Building AWS Glue Job using PySpark - Part:1(of 2) workshop before going to part-2.
When building ETL job, you perform Extract, Transform and Load operations. In this workshop, you learn how to use PySpark to perform these operations. You will learn about the following PySpark development:
-
Extract
a. Check source data schema
b. Query source data
-
Transform
a. Update data
b. Aggregate Functions
c. Merge & Split Data
-
Load
a. Write / Load Data at the Destination
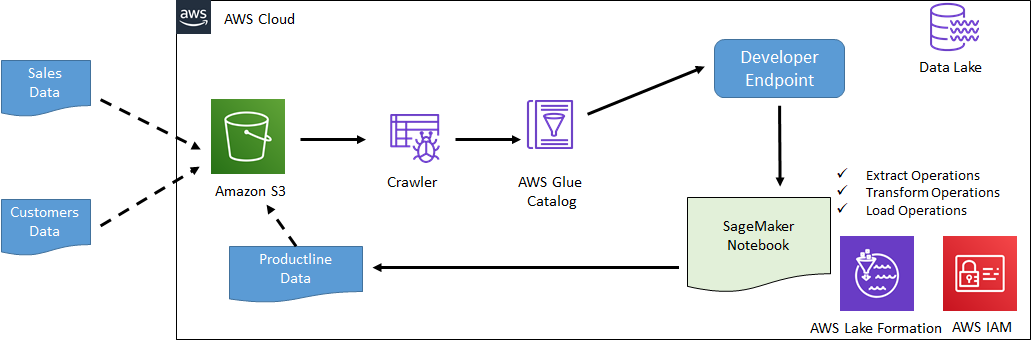
The following diagram shows the scenario used in the workshop part-2. Start the workshop