Building AWS Glue Job using PySpark - Part:1(of 2)
AWS Glue Jobs are used to build ETL job which extracts data from sources, transforms the data, and loads it into targets. The job can be built using languages like Python and PySpark. PySpark is the Python API for Spark and it used for big data processing. It can perform data tranformation on large scale data in fast and efficient way.
This workshop will be covered in two parts.
-
Part-1: You learn about setting up a data lake, creating development environment for PySpark and finally building a Glue job using PySpark.
-
Part-2: You learn about PySpark for various types of transformations especially when using AWS Lake Formation and Glue based data lake. These transformations can be used in AWS Glue job.
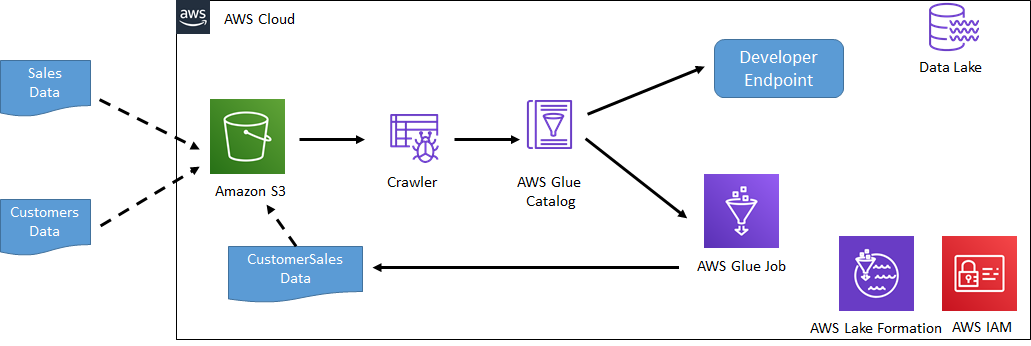
In part-1 workshop; you create data lake with two data sets sales and customers. Then you create Developer Endpoint to setup the development environment for PySpark. In the development environment, you will practice fundamental operations such as loading the data, merging two data sets into one and writing data back to S3. You will merge sales and customers data sets into CustomerSales data and write back to S3. Finally you create a Glue Job which will take the code you tried in the development environment to automate the task of merging of two data sets.
The following diagram shows the scenario you are going to build. Start the workshop