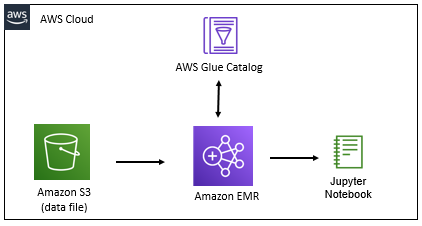
Using Amazon EMR with AWS Glue Catalog
Amazon EMR is a big data platform for processing large scale data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. Amazon EMR is easy to set up, operate, and scale for the big data requirement by automating time-consuming tasks like provisioning capacity and tuning clusters.
AWS Glue is used to catalog the data for the discoverability and accessibility purpose.
In this workshop, you launch an EMR cluster. You then use Jupyter Notebook to do PySpark based programming using AWS Glue Catalog table.
The following diagram shows the scenario you are going to build. Start the workshop