Using Amazon Redshift in AWS based Data Lake
A data lake is a centralized repository that allows to store all structured and unstructured data at any scale. The data in the data lake is used for different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning.
Amazon Redshift is a managed, petabyte-scale data warehouse service in the cloud.
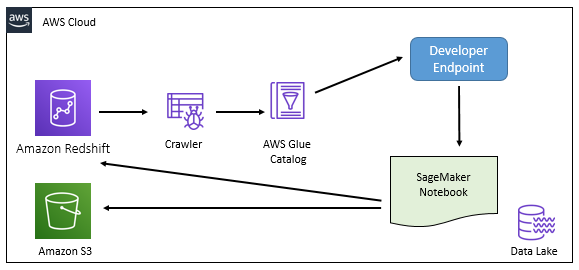
Most of the times, Redshift based warehouse is registered as data source to the data lake. In this workshop, you learn to configure data Lake and catalog Redshift database as the data source.
The following diagram shows the scenario you are going to build. Start the workshop