
Using Transient Amazon EMR Cluster
Amazon EMR is a big data platform for processing large scale data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. Amazon EMR is easy to set up, operate, and scale for the big data requirement by automating time-consuming tasks like provisioning capacity and tuning clusters.
In this exercise, you launch an EMR Transient cluster along with a step.
Step1: Pre-Requisite
You need to have an AWS account with administrative access to complete the exercise. If you don’t have an AWS account, kindly use the link to create free trial account for AWS.
Step2: Create S3 Bucket
You create S3 bucket and folders which are used as the source and destination data locations when you process data using EMR cluster.
-
Login to AWS Management Console and change the region to Ireland.
-
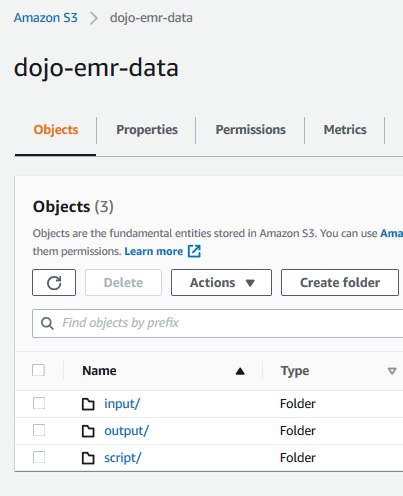
Goto S3 Management Console. Create a bucket with the name dojo-emr-data. If the bucket name is not available, create bucket with a name which is available. In this bucket, create three folders - input, output and script.
-
The input folder is used as the input location for the data to be processed by the EMR cluster. The output folder is the destination location where EMR cluster will write the processed data output. The script folder is used to store the script when creating a step within the EMR cluster.
-
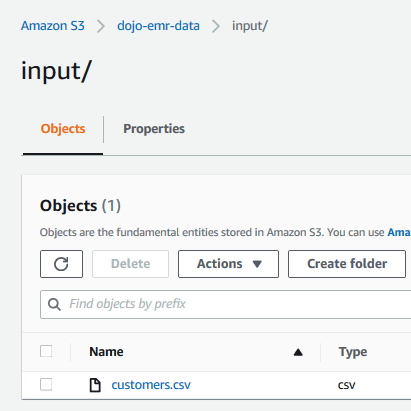
Download customers.csv file from the link. Upload the customers.csv file to the input folder.
-
Open the customers.csv file to get familiar with the data you will work with. It is a sample data. The S3 configuration is ready. In the next step, you configure script for the EMR step.
Step3: Prepare Script for the EMR Step
You configure script for the EMR Step in this part.
-
Create a local file with the name dojoemrtask.py and copy-paste the following code into it. The code reads customers.csv data from the S3 bucket, performs a transformation and then writes data back to the S3 bucket. The input and output locations have been parameterized in order to avoid hard-coding.
import sys from datetime import datetime from pyspark.sql import SparkSession from pyspark.sql.functions import * spark = SparkSession\ .builder\ .appName("SparkETL")\ .getOrCreate() customerdf = spark.read.option("inferSchema", "true").option("header", "true").csv(sys.argv[1]) customerdf = customerdf.select("CUSTOMERNAME","EMAIL") customerdf.write.format("parquet").mode("overwrite").save(sys.argv[2])`
-
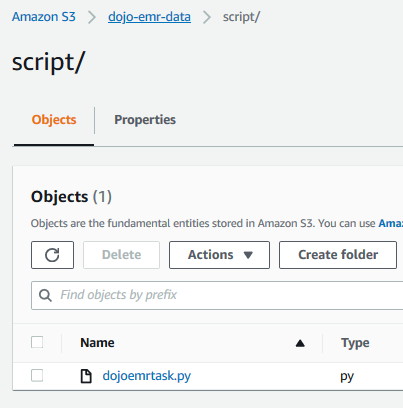
Upload the dojoemrtask.py file to the script folder under dojo-emr-data bucket. If you created bucket with a different name then use that bucket.
-
The next step is to launch EMR Cluster in the transient mode.
Step4: Launch EMR Cluster
You launch EMR cluster which is used to process data using PySpark based scripting.
-
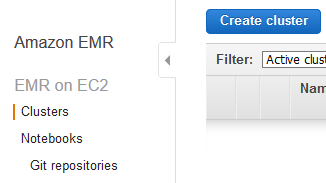
Goto the EMR Management console and click on the Create cluster button.
-
On the next screen, click on the Go to advanced options link.

-
On the next screen, use the default selection for the Release field. For the software configuration, make additional selection for Spark 2.4.7 along with the default selection.
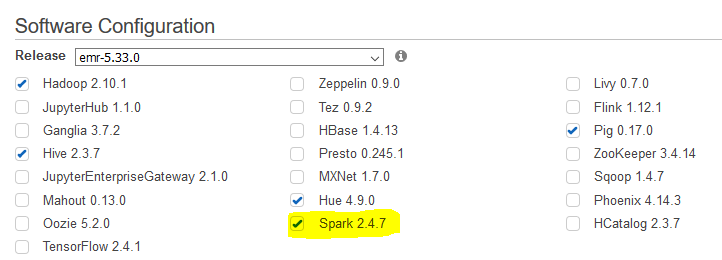
-
On the same screen, go the Steps (optional) section. Select Cluster auto-terminates option. Select Custom JAR for the step type and click on the Add step button.
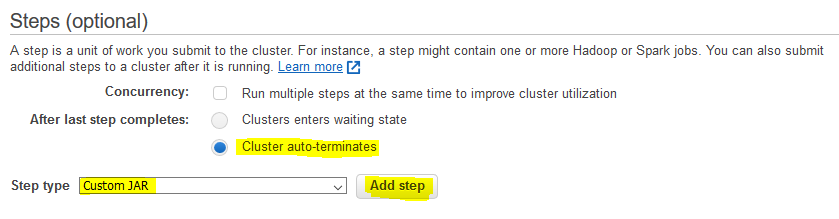
-
On the next popup screen, type in dojotask for the name. Type in command-runner.jar for the JAR location. Copy-Paste spark-submit s3://dojo-emr-data/script/dojoemrtask.py s3://dojo-emr-data/input/customers.csv s3://dojo-emr-data/output/taskoutput/ for the Arguments. If you created bucket with different name, use that one. You are providing three arguments - command to submit spark task, input file location and output folder location. The script above uses the input and output location in the code. Finally, click on the Add button.
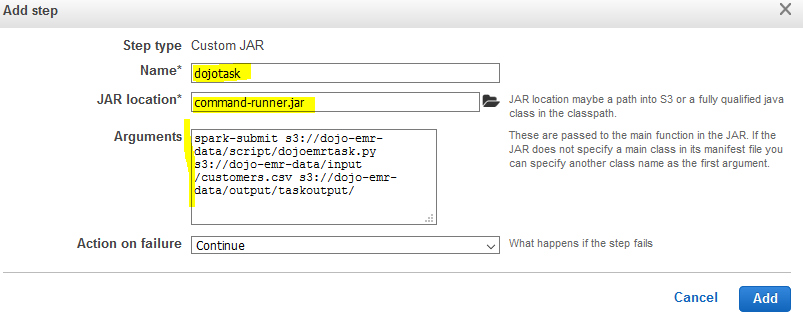
-
The step got added. Click on the Next button.
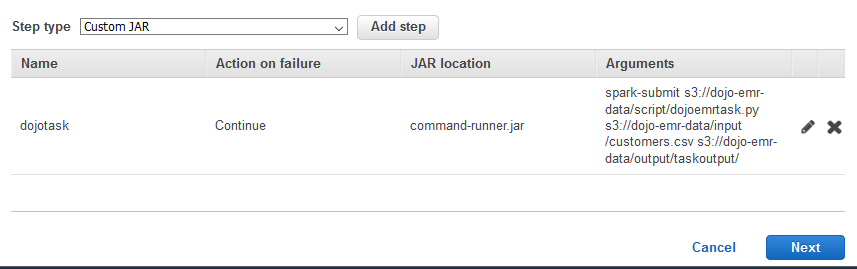
-
On the next screen, select Uniform instance groups for the Instance group configuration. Select default VPC for the network and select one the default subnet. Keep rest of the configuration to the default and click on the Next button.
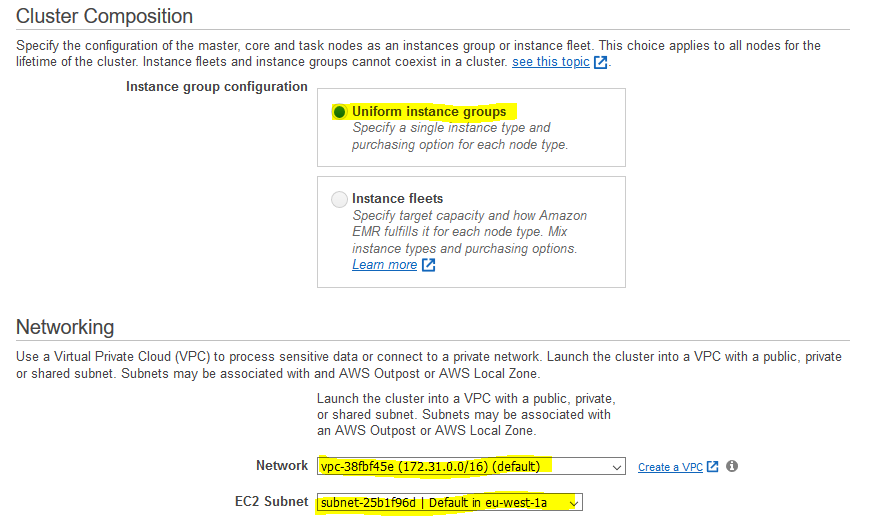
-
On the next screen, type in dojocluster for the cluster name. Keep rest of the configuration to the default and click on the Next button.
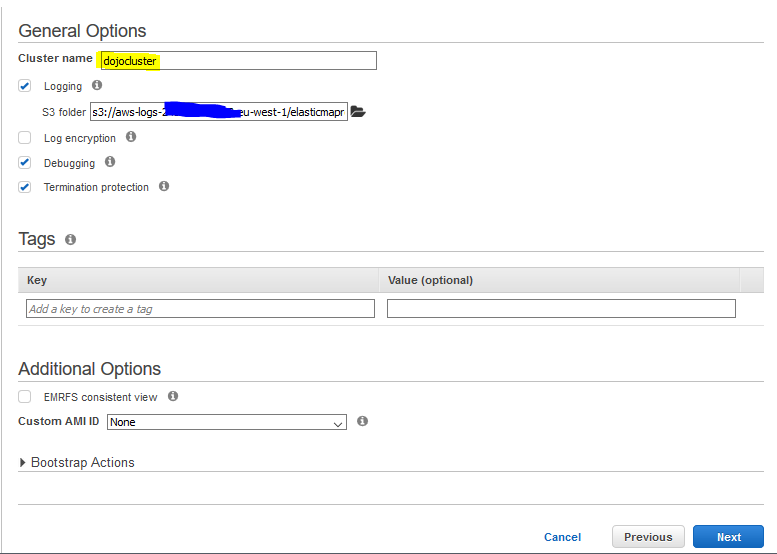
-
On the next screen, keep the configuration to the default and click on the Create cluster button.
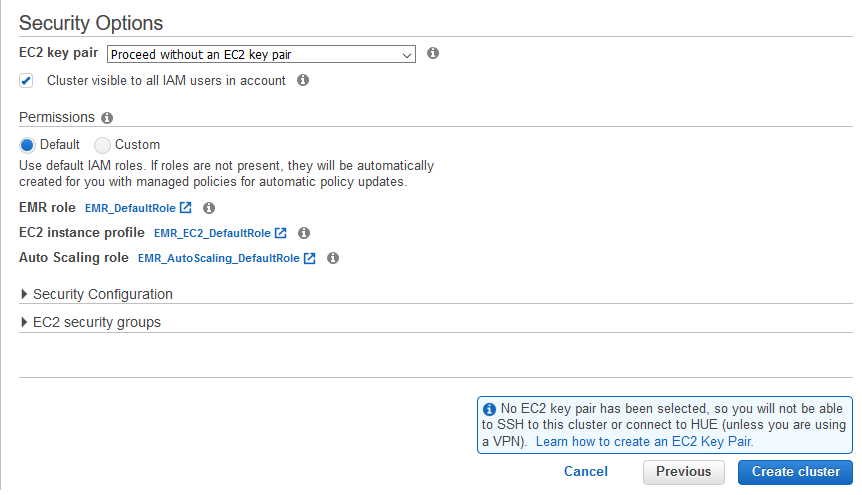
-
The cluster creation will start. The cluster will start and then it will execute the step. Finally, since the cluster is configured as the transient cluster, it will terminate itself. Wait till the cluster status changes to Terminated. You can see that the cluster has completed the step before termination,

-
Since the step is completed, you can verify the step outcome in the output folder of the S3 bucket.
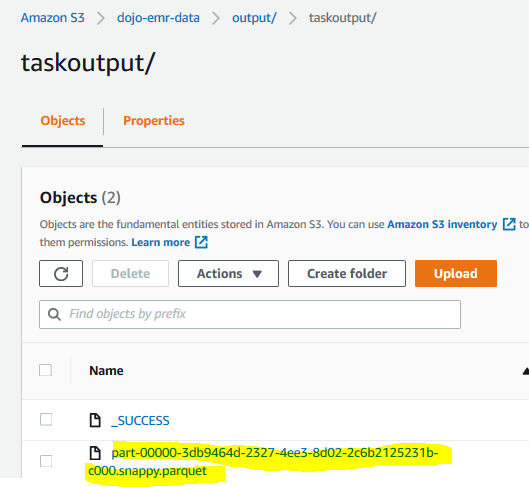
-
The exercise finishes here. Follow the next step to clean up the resources so that you don’t incur any cost post the exercise.
Step5: Clean up
Clean up the following resources.
Delete dojo-emr-data S3 Bucket.
Thanks for using the exercise.