
Data Lake Export in Amazon Redshift
Amazon Redshift is the cloud data warehouse in AWS. Amazon Redshift provides seamless integration with other storages like Amazon S3. It enable a very cost effective data warehouse solution where the warm data can be kept in Amazon Redshift storage while the cold data can be kept in the S3 storage. The user can access the S3 data from Redshift in the same way, the data is accessed from the Redshift storage itself. Amazon Redshift enables S3 data access from Amazon Redshift.
Redshift uses Data Lake Export feature which allows to unload the result of a Redshift query to the S3 data lake in Apache Parquet format. This way, Redshift can offload the cold data to the S3 storage.
In this exercise, you learn unload to S3 method in Amazon Redshift.
The AWS Resource consumption for the exercise does not fall under AWS Free Tier.
Step1: Pre-Requisite
You need to have an AWS account with administrative access to complete the exercise. If you don’t have an AWS account, kindly use the link to create free trial account for AWS.
Step2: Create S3 Bucket
You create the S3 bucket which is used to unload data from the Redshift database.
-
Login to the AWS Console and choose Ireland as the region.
-
Goto S3 Management studio. Create an S3 bucket with name dojo-lake. If the bucket name is not available, create bucket with a name which is available. Create a folder orders into the bucket.
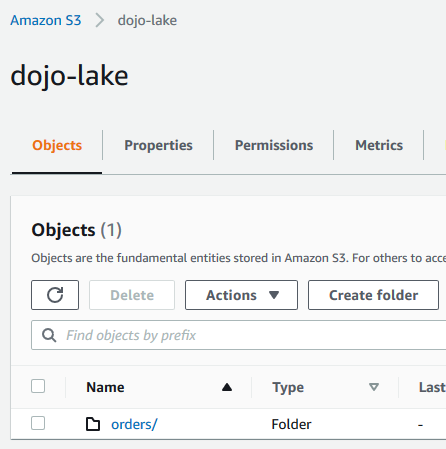
-
The S3 bucket is ready. The next step is to create IAM Role for the Redshift cluster.
Step3: Create IAM Role.
You create IAM Role for the Redshift cluster which is used to provide access to the S3 bucket.
-
Goto the IAM Management console and click on the Roles menu in the left and then click on the Create role button.
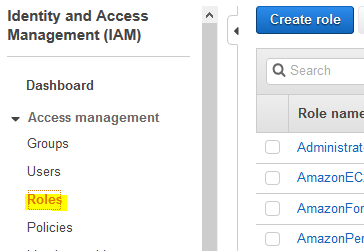
-
On the next screen, select Redshift - Customizable as the service \ use case and click on the Next: Permissions button.
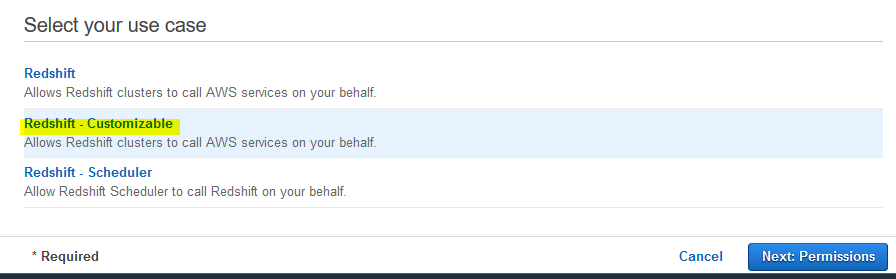
-
On the next screen, select PowerUserAccess as the policy and click on the Next: Tags button.
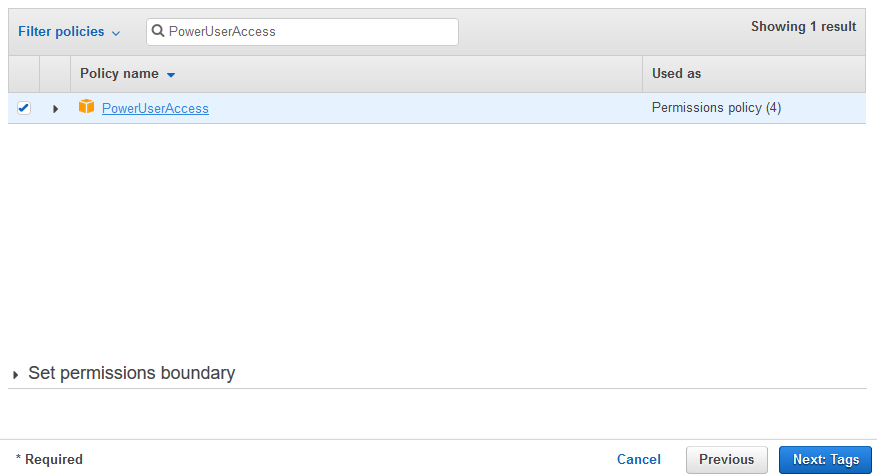
-
On the next screen, click on the Next: Review button.
-
On the next screen, type in dojoredshiftrole as the role name and click on the Create role button.
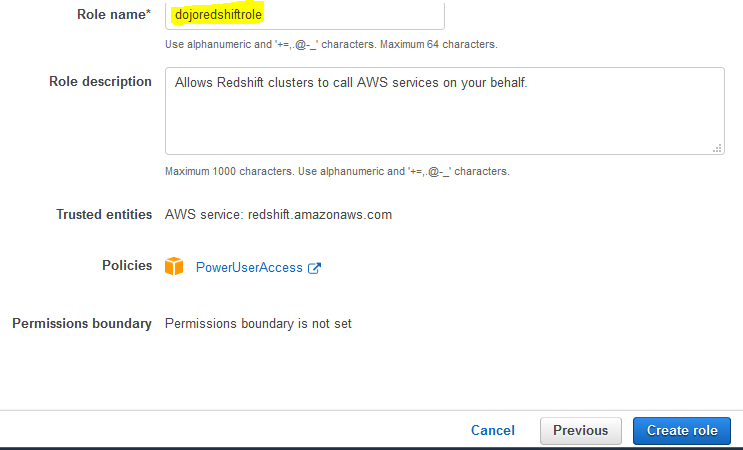
-
The role is created in no time. Please make note of the Role ARN as you need it later in the exercise. The next step is to launch the Redshift cluster.
Step4: Launch Redshift Cluster
You launch a Redshift cluster which is used to unload the query data to the s3 bucket.
-
Goto Redshift Management Console and click on the Create cluster button.
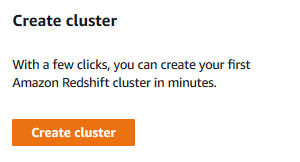
-
On the next screen, type in dojoredshift for the cluster identifier and select Free trial option.
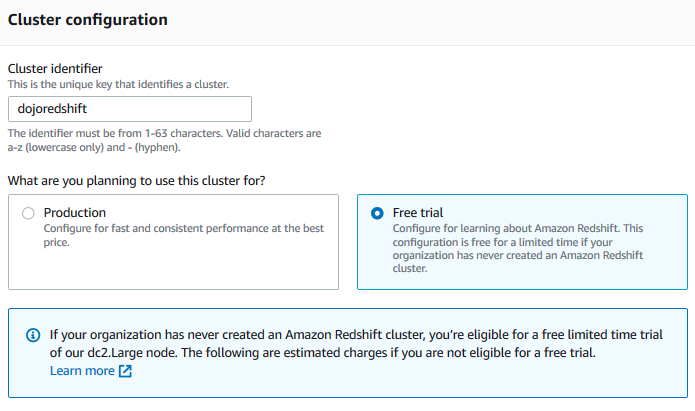
-
On the same screen, in the Database configurations section, type in Password1! for the master user password field. Keep rest of the fields as the default.
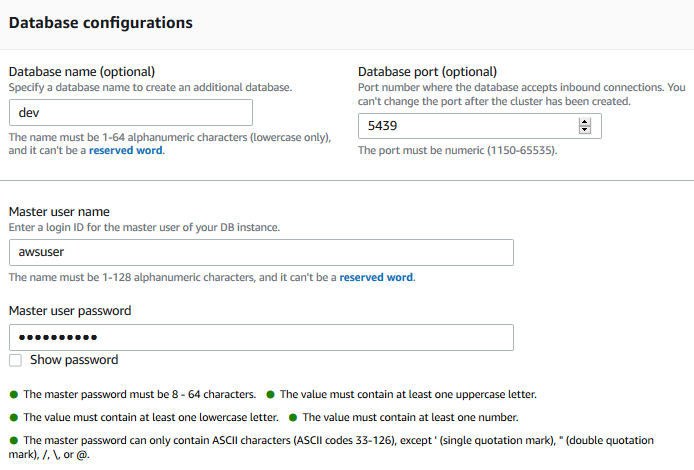
-
On the same screen, expand Cluster permissions (optional) section. Select dojoredshiftrole as the IAM Role and click on the Associate IAM Role button (please make sure you click this button to add the role to the cluster). Finally click on the Create cluster in the bottom of the screen.
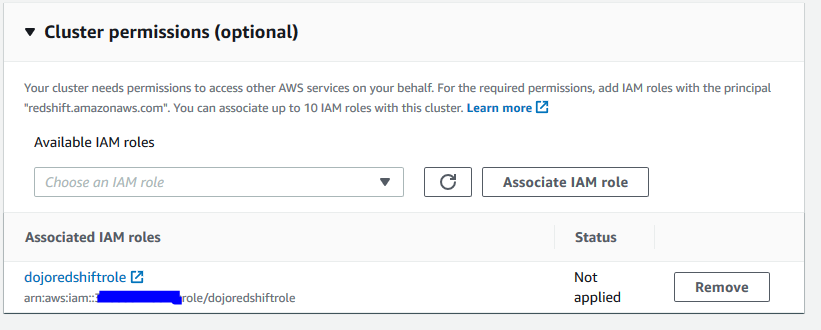
-
It will take a moment to create the Redshift cluster. Wait till the status of the cluster changes to Available.
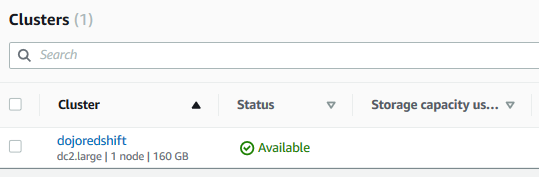
-
Few things to remember about the cluster which will be useful later.
cluster identifier: dojoredshift
username: awsuser
password: Password1!
database: dev
-
The cluster is ready. Let’s use it to unload query result to the S3 bucket.
Step5: Unload Data from Redshift Database
In this step, you first create orders table and insert sample data into it. Then you unload a query result to the s3 bucket orders folder.
-
In the Redshift Management Console, click on the EDITOR menu in the left. It will open the Connect to database popup. Select Create new connection option. Select dojoredshift as the cluster. Type in dev for the database. Type in awsuser for the user and Password1! for the password. Finally click on the Connect to database button to connect to the cluster.
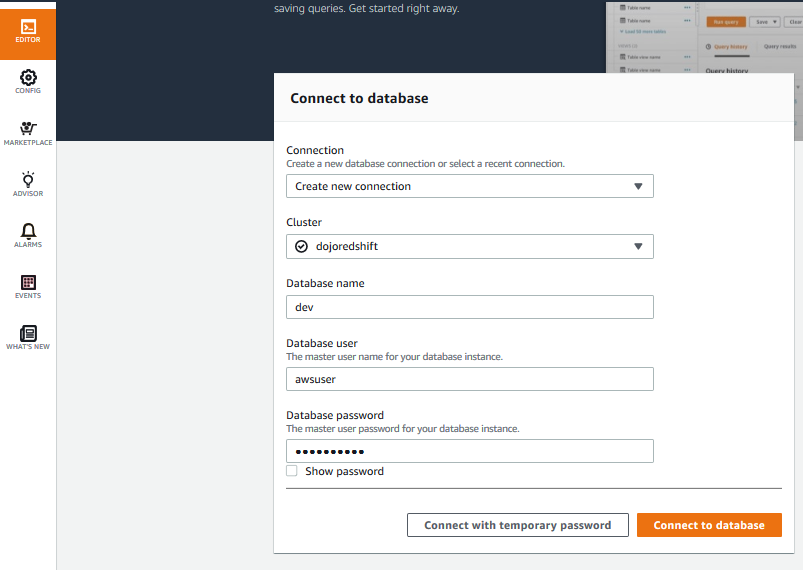
-
On the next screen, run the following SQL statement to create orders table.
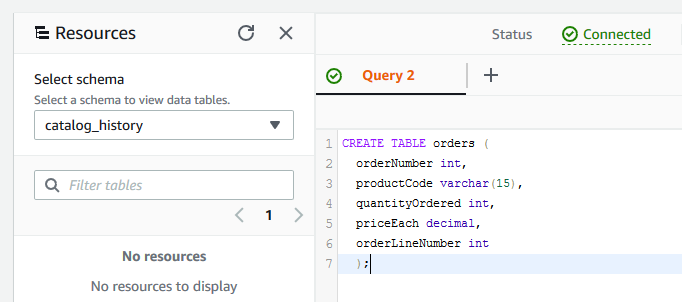
CREATE TABLE orders ( orderNumber int, productCode varchar(15), quantityOrdered int, priceEach decimal, orderLineNumber int );`
-
You then run the following SQL statement to insert records for the orders table.
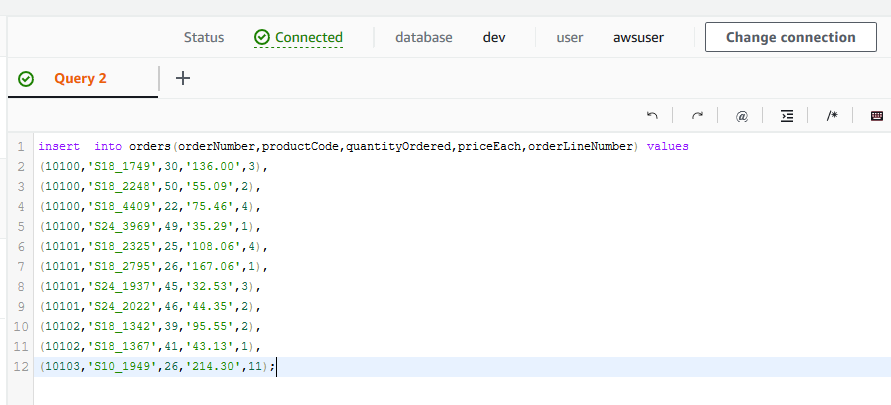
insert into orders(orderNumber,productCode,quantityOrdered,priceEach,orderLineNumber) values (10100,'S18_1749',30,'136.00',3), (10100,'S18_2248',50,'55.09',2), (10100,'S18_4409',22,'75.46',4), (10100,'S24_3969',49,'35.29',1), (10101,'S18_2325',25,'108.06',4), (10101,'S18_2795',26,'167.06',1), (10101,'S24_1937',45,'32.53',3), (10101,'S24_2022',46,'44.35',2), (10102,'S18_1342',39,'95.55',2), (10102,'S18_1367',41,'43.13',1), (10103,'S10_1949',26,'214.30',11);`
-
You now run the following query to unload a query result into the s3 bucket. In the query, if you created S3 bucket with a different name; then replace dojo-lake with that. Replace {REDSHIFT-ROLE} with the ARN of the Redshift IAM Role you created earlier.
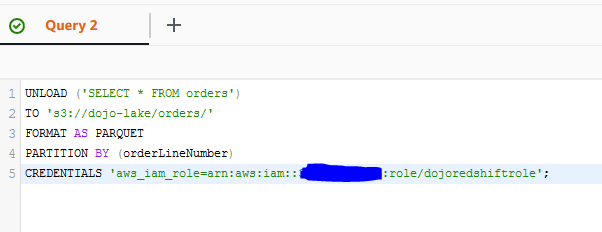
UNLOAD ('SELECT * FROM orders') TO 's3://dojo-lake/orders/' FORMAT AS PARQUET PARTITION BY (orderLineNumber) CREDENTIALS 'aws_iam_role={REDSHIFT-ROLE}'; -
In the query above, you tried to unload result of the query SELECT * FROM orders to the s3 bucket. You also partitioned the data files based on the field orderLineNumber. You can go to S3 bucket and see the query result stored in partitioned files under the orders folder.
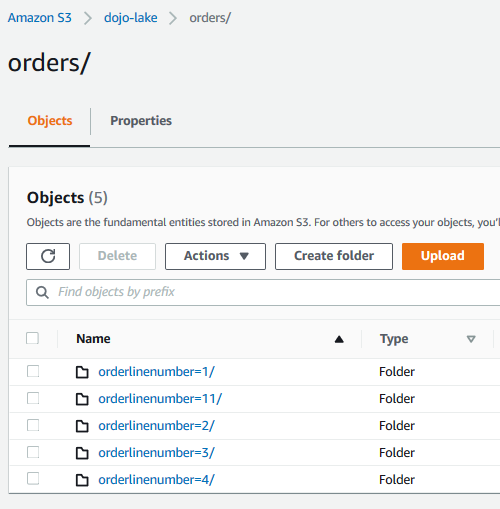
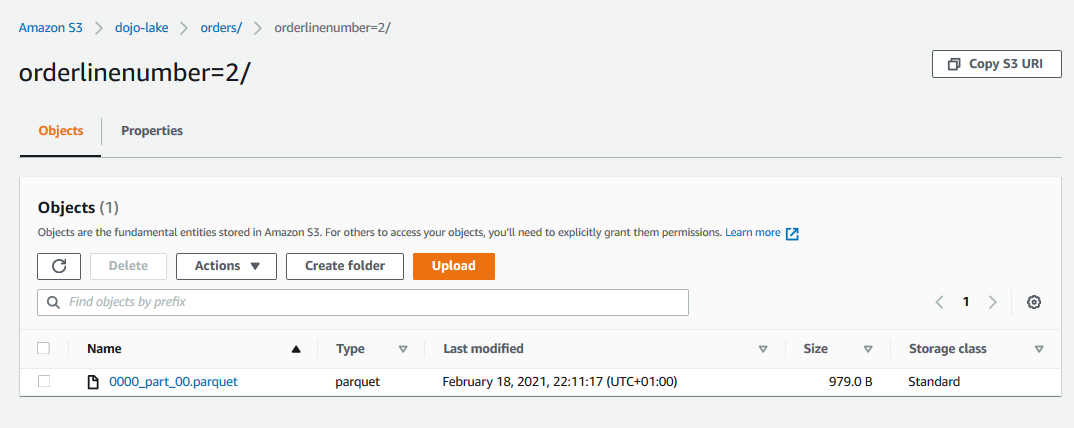
-
This was a quick exercise to understand how to unload query result from the Redshift cluster to the S3 bucket. Follow the next step to clean-up the resources so that you don’t incur any cost post the exercise.
Step6: Clean up
Delete dojoredshift Redshift Cluster.
Delete dojo-lake S3 Bucket.
Delete dojoredshiftrole IAM Role.
Thanks and hope you enjoyed the exercise.