You create Amazon S3 bucket and upload data for the data lake. For this workshop, you are uploading data manually but in actual production usage the data is uploaded using data ingestion services / pipeline such as AWS Glue, Amazon Kinesis etc.
-
Login to the AWS console and select Frankfurt as the region. Goto S3 Management console, use + Create bucket button to create a new bucket with name dojo-data-lake. If the bucket name is not available, then use a different name which is available. Please make sure the bucket is created in the Frankfurt region.

-
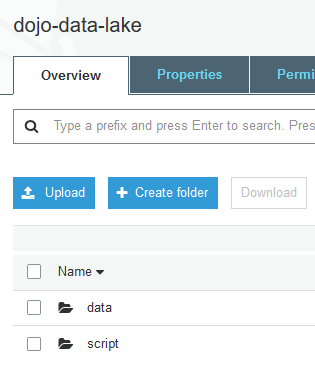
Click on the dojo-data-lake bucket to open it. Within the dojo-data-lake, create two folders data and script using the + Create folder button. The data folder is used to keep the data lake data while the script folder is used by Glue job to store the script.
-
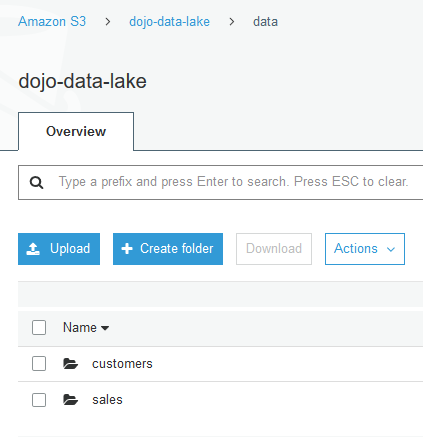
Click on the data folder to open it. Within the data folder, create two folders customers and sales using the + Create folder button.
-
Click to open customers and sales folders one by one and upload customers.csv and sales.csv files in the customers and sales folders respectively. Use Upload button to upload the files. The customers.csv and sales.csv files are available for download using the following links -
-
The data is ready. Let’s start with the data lake configuration.