You now create IAM Role which is used by the AWS Glue crawler, job and developer endpoint to perform tasks like data catalog creation, data transformation / processing.
-
Login to your AWS account and go to IAM Management Console. Click on the Roles menu in the left side and then click on the Create role button.
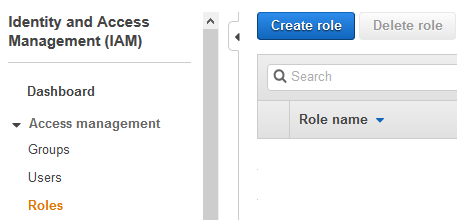
-
On the next screen, select Glue as the AWS Service. Click on the Next: Permission button.
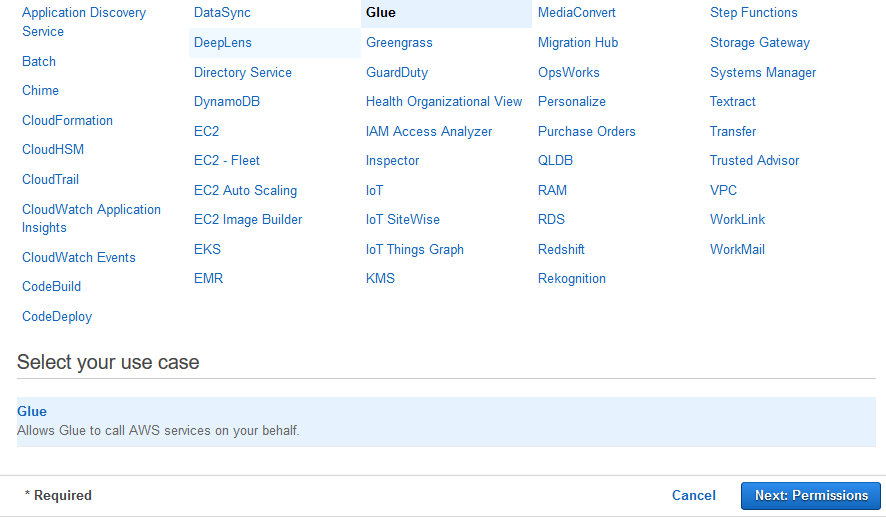
-
On the next screen, select PowerUserAccess as the policies. The workshop is using this policy to simplify the authorization. However, in the production implementation, you select minimum required permission for the role. Click on the Next: Tags button.
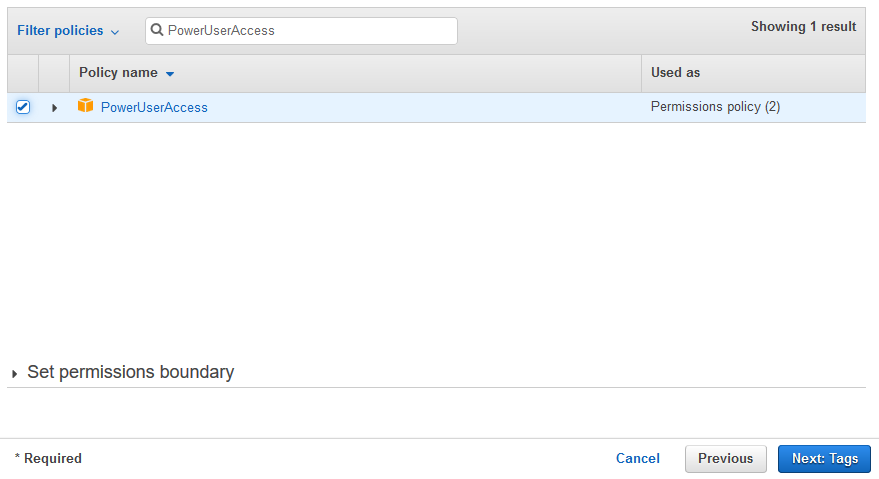
-
Click on the Next: Review button on the next screen.
-
On the next screen, enter the Role name as dojogluerole and click on the Create role button.
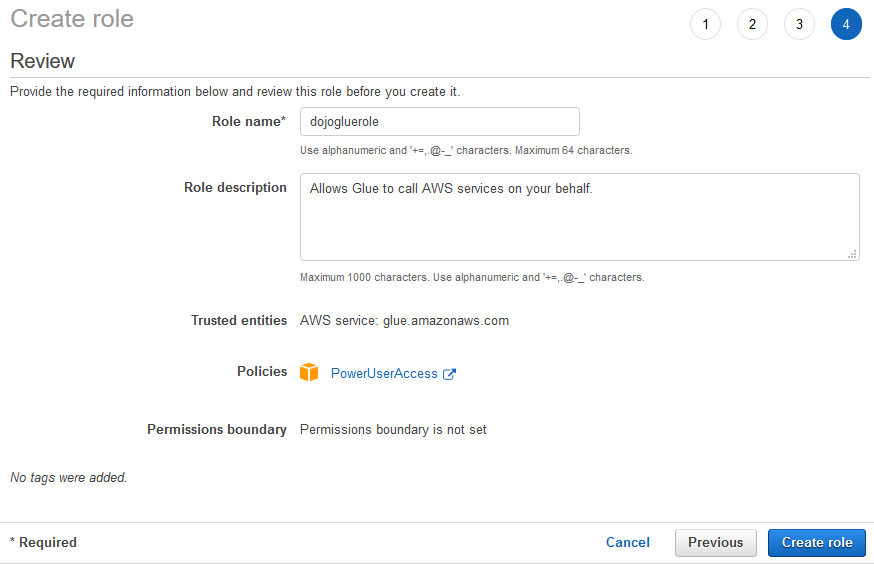
-
The role is created in no time. The next task is to create the S3 bucket for the data lake.