You will create an Amazon S3 bucket which serves many purposes. It will be used by the PySpark code later as temporary bucket location. It is also used by the PySpark code to write data in the S3 bucket.
-
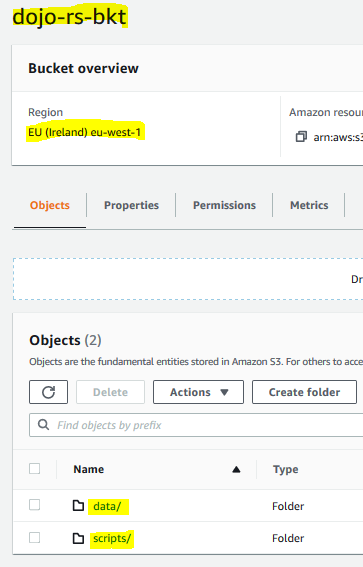
Go to the S3 Management Console and create a S3 bucket with name dojo-rs-bkt. If the bucket name is not available, then use a name which is available. In this bucket, create two folders data and scripts.
-
The bucket is ready. The data folder is used to write the data in S3 and the scripts folder is used as temporary folder location in the PySpark code.
-
In the next step, you launch Redshift Cluster and create a table in the database.