You will use a sample data to train the model for the Amazon Personalize. Download the data from the link. The sample data has movies watched by customers with timestamp. The workshop will use this data to build a model which helps in providing recommendations for the customers.
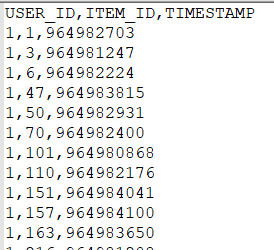
The csv file has the following fields:
1st field - USER_ID - Represents the customer. The movie recommendations are provided for USER_ID.
2nd field - ITEM_ID - Represents the movie watched by a customer. The recommendations are provided about the movies (ITEM_ID) for a customer (USER_ID).
3rd field - TIMESTAMP - Timestamp when the movies was watched by the customer.
These three fields are mandatory for the training data in Personalize.
The data looks like the following:
You will upload the sample data file to a S3 bucket.
Login to AWS Console and choose Ireland as the region.
Create a bucket with name dojo-personalize-records. If this bucket name is not available, use a bucket name which is available. Upload the sample_data.csv file into the bucket created.
The training data is ready. The next step is to configure access for the S3 bucket.