Amazon Comprehend can find insights and relationships in text in many ways. Let’s start with detecting the dominating language of the text and entities in the text. The Entity Recognition API returns the named entities (“People,” “Places,” “Locations,” etc.) that are automatically categorized based on the provided text. The exercise is using a sample text from wiki about Luxembourg. You can use your own text if you want.
-
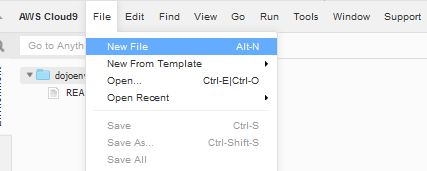
Goto the AWS Cloud9 console and click on the New File option under the File menu.
-
A new Untitled1 file gets created. Write the following code in the Untitled1 file.
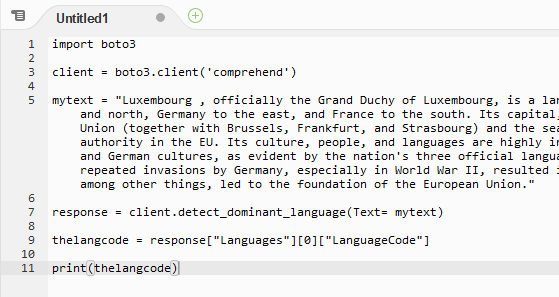
import boto3 client = boto3.client('comprehend') mytext = "Luxembourg , officially the Grand Duchy of Luxembourg, is a landlocked country in Western Europe. It is bordered by Belgium to the west and north, Germany to the east, and France to the south. Its capital, Luxembourg City, is one of the four official capitals of the European Union (together with Brussels, Frankfurt, and Strasbourg) and the seat of the Court of Justice of the European Union, the highest judicial authority in the EU. Its culture, people, and languages are highly intertwined with its neighbours, making it essentially a mixture of French and German cultures, as evident by the nation's three official languages: French, German, and the national language of Luxembourgish. The repeated invasions by Germany, especially in World War II, resulted in the country's strong will for mediation between France and Germany and, among other things, led to the foundation of the European Union." response = client.detect_dominant_language(Text= mytext) thelangcode = response["Languages"][0]["LanguageCode"] print(thelangcode)`
-
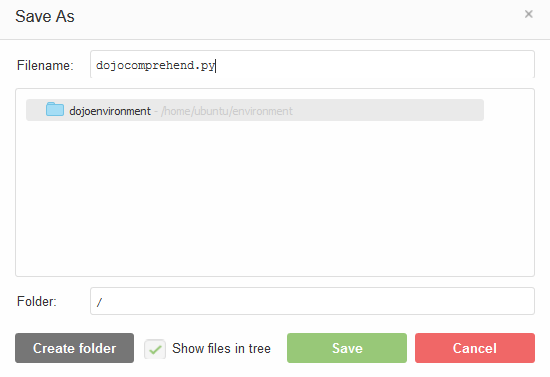
In the code above, you first create client to comprehend. Then you call detect_dominant_language method to find and print the dominating language of the text. The text is provided in the mytext variable. Click on the Save option under the File menu. On the Save As popup, type in dojocomprehend.py as the file name and click on the Save button. The code is saved in the file.
-
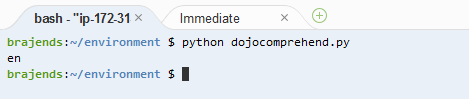
In the console window, execute python dojocomprehend.py command to run the dojocomprehend.py code. The code execution finishes in no time and will print the dominating language.
-
The first part of the code is ready. It detected the language of the text. Let’s add next part of the code in dojocomprehend.py file and detect entities and their types. Append the following code to the existing code and save the file.
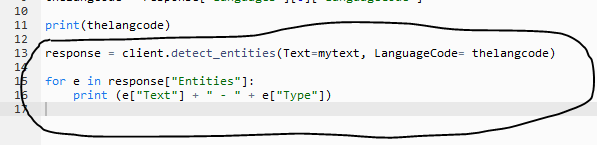
response = client.detect_entities(Text=mytext, LanguageCode= thelangcode) for e in response["Entities"]: print (e["Text"] + " - " + e["Type"])`
-
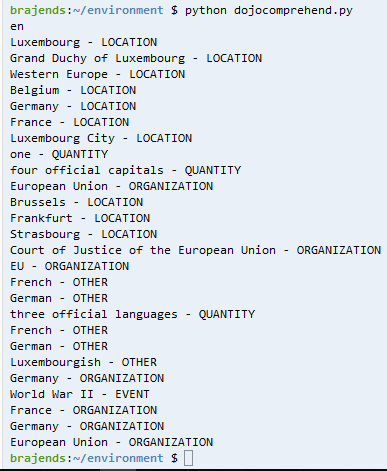
In the code above, you extend the code and use detect_entities method to detect the entities in the text. You then loop through the detected entities to print them along with their types. In the console window, execute python dojocomprehend.py command to run the dojocomprehend.py code to print the entities.
-
This was a good start. In the next step, you update the code to detect key phrases.