Before writing the Glue Job for the ETL purpose; one has to check the schema of the data to understand it. You can see the schema of the data in the Lake Formation \ Glue catalog table. You can also see the schema of the data using PySpark code. You will learn about schema related PySpark code in this task.
- Goto the AWS Glue console. Click on the Notebooks menu on the left, select the notebook aws-glue-dojonotebook and click on the Open notebook button. On the popup window, click OK.
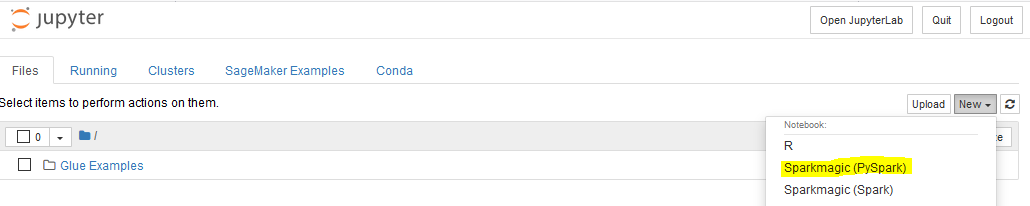
- It will open jupyter notebook in a new window. Click on New in the dropdown menu and select Sparkmagic (PySpark) option.
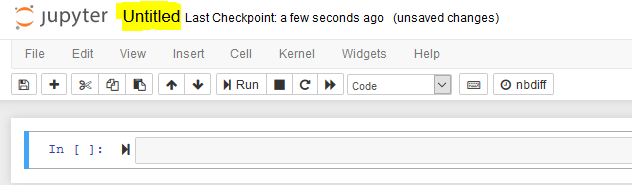
- It will open a notebook file in a new window. Click on Untitled to rename the notebook.
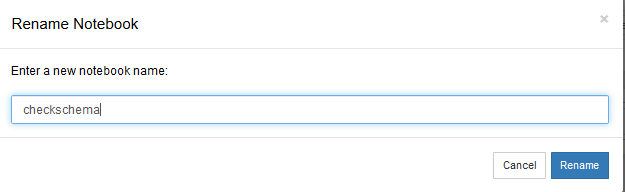
- In the popup window, update the name of the notebook from Untitled to checkschema. Click Rename.
- Copy and paste the following PySpark snippet (in the black box) to the notebook cell and click Run. It will create Glue Context.
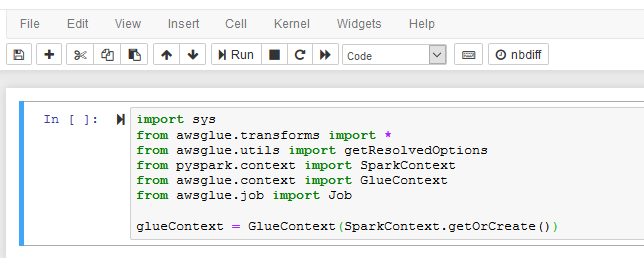
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(SparkContext.getOrCreate())
- It takes some time to start SparkSession and get Glue Context. Wait for the confirmation message saying SparkSession available as ‘spark’..
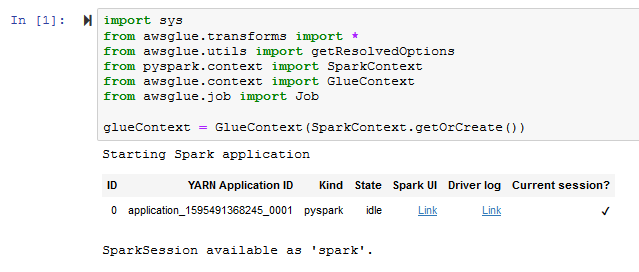
- Copy the following PySpark snippet in the notebook cell and click Run. Wait for the execution to finish. It will load dynamicframe for the data catalog table sales in the database dojodatabase.
salesDF = glueContext.create_dynamic_frame.from_catalog(
database="dojodatabase",
table_name="sales")
- Run the following PySpark snippet to check the schema of the sales table. You will see the column names and their data types.
salesDF.printSchema()
- Run the following PySpark snippet to check number of rows in the sales table.
salesDF.count()
- These are the methods to check the schema of the data using PySpark code. Click on the Close and Halt option under Files menu to close the notebook. Confirm if it asks to Leave Page.
- In the next task, you learn about the data query.