The data lake is ready with the data catalog which gives access to the data stored in Amazon S3 bucket. It is time to configure access for the dojogluerole role to the sales and customers tables as this role be used by Glue Job and Developer Endpoint to process / transform the data.
-
On the AWS Lake Formation console, click on the Tables option on the left menu. Select the Sales table and click on the Grant menu option under the Action dropdown menu.
-
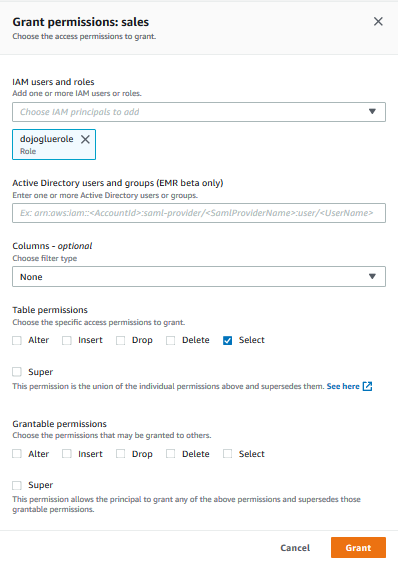
On Grant permissions screen, select dojogluerole for the IAM users and roles field. Choose only Select permissions from the Table permissions. Leave rest of the fields as shown on the screen below and then click on the Grant button. The permission for the dojogluerole is configured.
-
Next, select the customers table and click on the Grant menu option under the Action dropdown menu.
-
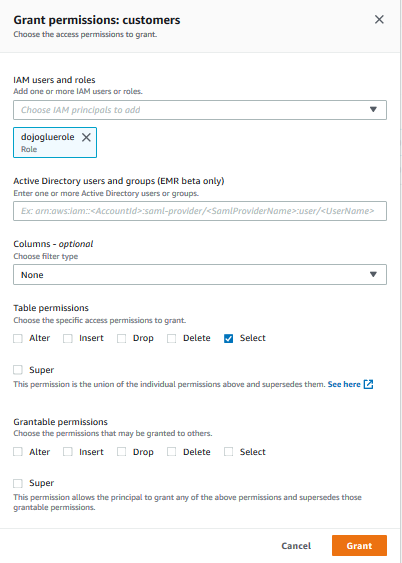
On Grant permissions screen, select dojogluerole for the IAM users and roles field. Choose only Select permissions from the Table permissions. Leave rest of the fields as shown on the screen below and then click on the Grant button. The permission for the dojogluerole is configured.
-
The permissions are configured for both the tables. The next task is to configure Developer Endpoint to create the development environment for the Glue Job.